Scope and Progress
The Discovery Lab seeks to advance the ability to construct, use and study a large-scale knowledge graph that integrates knowledge across heterogeneous scientific content and data. The knowledge graph will allow for a deeper, richer use of content and data across a larger span of domains than possible thus far.
Scope
The project is split in five work packages.
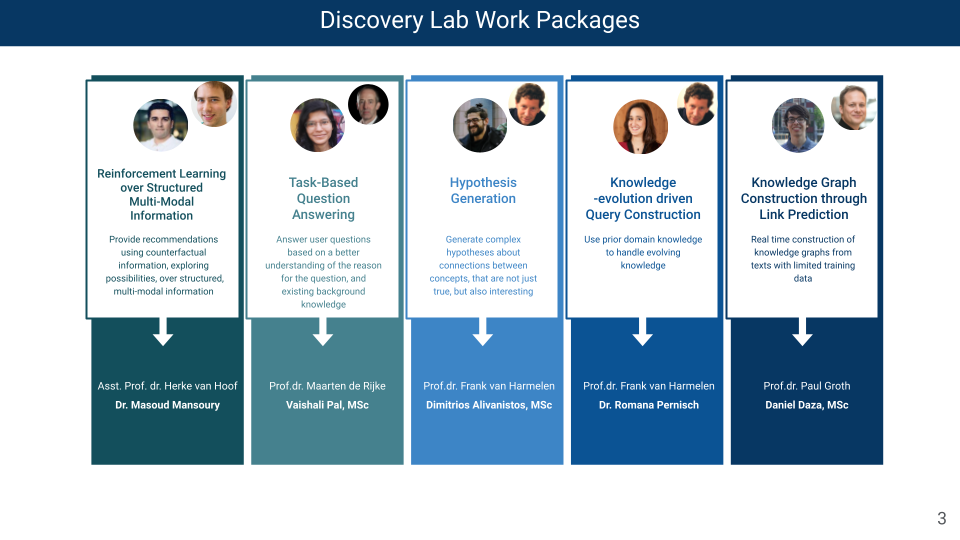
Knowledge Graph construction through link prediction and text understanding
Knowledge Graph construction and updating from natural language sources is a key capability for any scientific knowledge graph. One of the targets of the lab is the creation of a knowledge graph updating service that feeds in real-time on a stream of scientific literature and will produce high quality knowledge graph updates that will enable high precision alerts.
Reinforcement learning over structured multi‐modal information
When providing recommendations, it is often possible to get some evaluation of that recommendation (‘was it useful?’) while counterfactual information is often not available (‘would another recommendation have been more useful?’). These circumstances can make it difficult to train models using regression or classification techniques. In the lab we investigate the use of reinforcement learning which can work with structured multi-modal information such as user context, knowledge graphs, or text as inputs. As a result the system generates structured recommendations, such as proposals for promising looking lab experiments.
Task‐Based Question Answering
In the lab we want to advance the state-of-the-art in question answering. We focus on challenging scenarios that requires the QA model to reason, gather, and synthesize disjoint pieces of information within the context to generate an answer. Moreover, we do so in the task-based setting of a research platform with a global perspective, aimed at generating partial answers from background knowledge, combined with a task-based perspective. The goal is to generate actionable answers that fit the research task at hand, and a mixed-initiative perspective, that is aimed at eliciting information about research tasks and designs from users of the research platform so as to optimize the QA responses being generated.
Hypothesis Generation
Many disciplines have managed to amass such large amounts of data that data-gathering platforms are no longer restricted to passive “query answering” anymore. Instead of expecting researchers to formulate hypotheses (and subsequently test these against the data), we will build the capacity to propose plausible new hypotheses. The challenge will be to extend the prediction of micro-hypotheses to hypotheses of more generality and complexity. This will require advances in knowledge graph completion (extending current techniques to completion with subgraphs, rather than with simple links), and in knowledge graph generalization.
Knowledge‐driven query construction
Tasks such as constructing meta-reviews in medical research, or writing literature surveys in general, involve finding evidence using manual or semi-automatic methods, which are time-consuming and suffer from low precision. To overcome this difficulty, we will investigate the knowledge-based construction of complex queries where prior domain specific knowledge is used to constrain the space of possible queries to be generated. We are looking into the construction of queries, to find answers to long standing searches (monitoring over time, when KG changes) and to improve the search over large corpora of data with the help of KGs, for example using embeddings.
How we work
In the lab, we work with so-called spike projects. These are driven by business interests and aligned with the work packages.
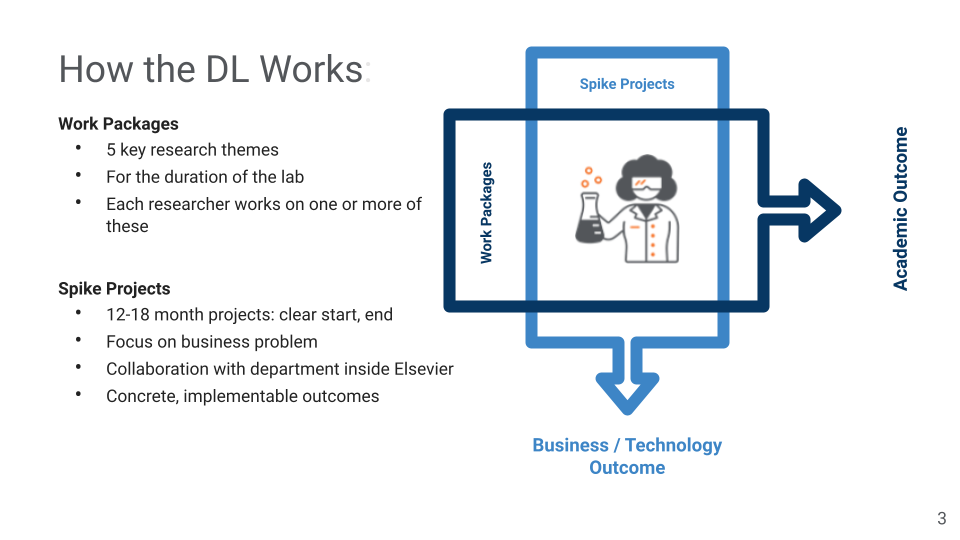
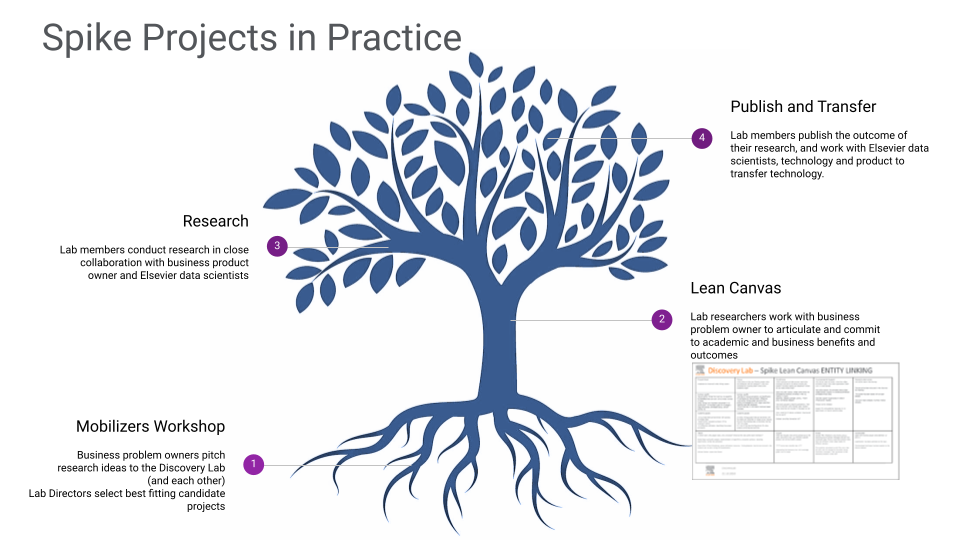
These spikes are chosen based on a process in which initial ideas are proposed in the mobilizers workshops. If selected by the board of directors, then these ideas are further detailed in the lean canvas. After that research on this topic takes place, followed by publication of the results and transfer to the respective team inside the company.
Progress
The efforts in the lab have led to a very nice output, both from an academic, as well as a business perspective. Find an overview of lab related publications here This image shows an overview of the outputs from the lab until April 2024.
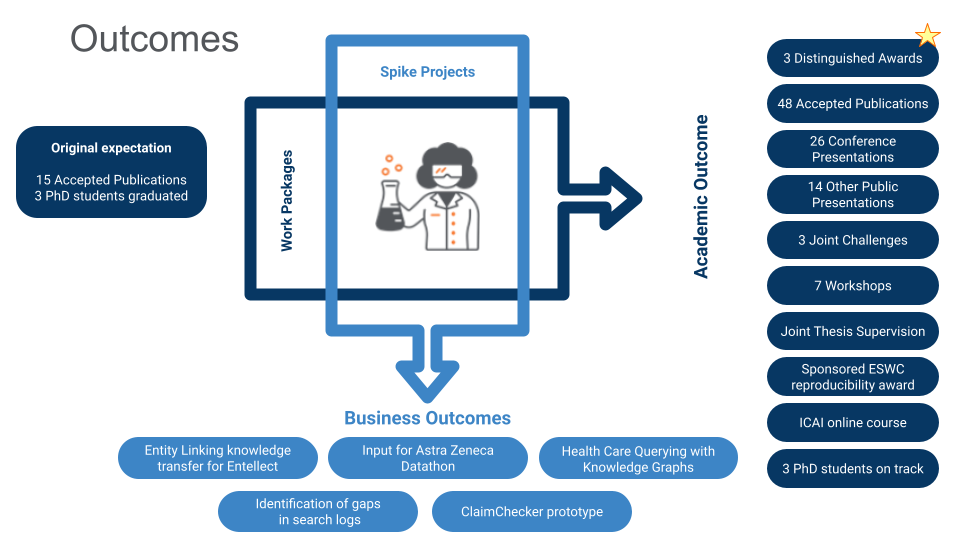
The initial planning for the lab foresaw a run time of 5 years. Because of hiring difficulties, this was extended to 5.5 years. The 3 Phd students are well on track to graduate and we have reached the goal of 3 publications for each work package.
